

Large Language Models (LLMs) have significantly reshaped the landscape of machine learning by moving away from traditional end-to-end learning models and instead relying on pretrained models optimized through carefully crafted prompts. This shift introduces a fascinating dichotomy in optimization approaches, contrasting traditional methods that involve training neural networks from scratch with gradient descent in a continuous numerical space, and emerging techniques focused on optimizing input prompts for LLMs in a discrete natural language space.
The Paradigm Shift: LLMs as Function Approximators
A crucial question raised by this shift is whether a pretrained LLM can function as a system parameterized by its natural language prompt, much like neural networks are parameterized by numerical weights. This new approach challenges existing paradigms and encourages researchers to rethink the fundamental nature of model optimization and adaptation in the era of large-scale language models.
Applications of LLMs in Optimization and Multi-Agent Systems
LLMs have been widely applied to various tasks, including planning for embodied agents, solving optimization problems, and enhancing learning processes through natural language supervision. For example, they have been used to generate solutions based on previous attempts and the associated losses, and have shown promise in providing supervision for visual representation learning and developing zero-shot classification requirements for images.
Moreover, optimization and prompt engineering have become important areas of research, with a variety of methods developed to leverage the reasoning capabilities of LLMs. Automated prompt optimization methods have been proposed to reduce the manual effort involved in crafting effective prompts, while LLMs have demonstrated their potential in multi-agent systems, where they take on different roles to collaboratively solve complex problems.
However, these existing methods typically focus on specific applications or optimization approaches, without fully exploring the potential of LLMs as function approximators parameterized by natural language prompts. This gap has paved the way for new frameworks that aim to bridge the divide between traditional machine learning paradigms and the unique capabilities of LLMs.
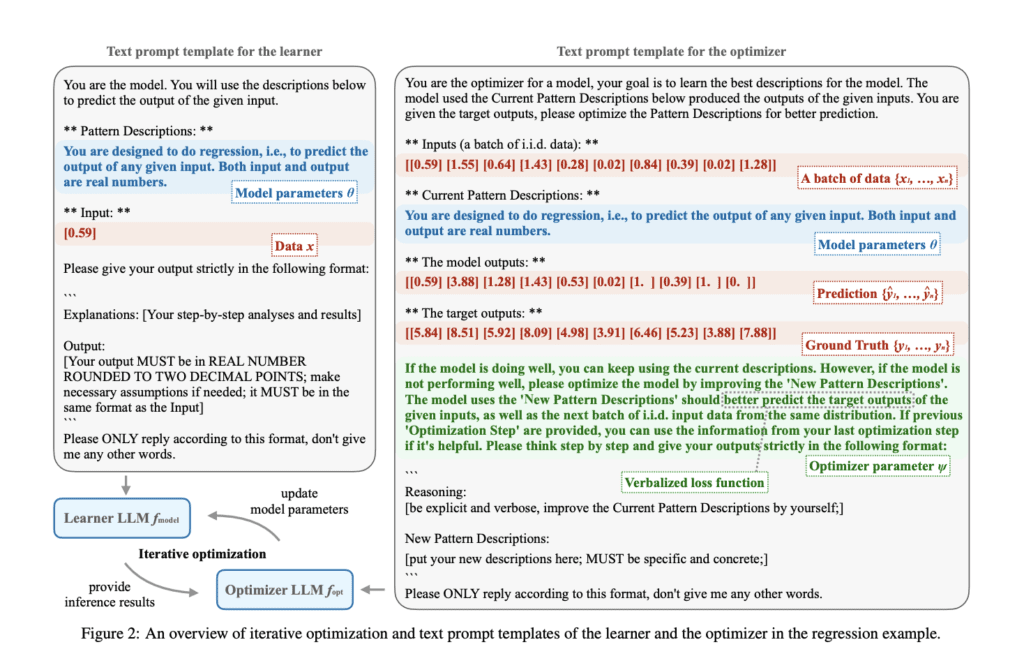
The Verbal Machine Learning (VML) Framework
Researchers from the Max Planck Institute for Intelligent Systems, the University of Tübingen, and the University of Cambridge have introduced the Verbal Machine Learning (VML) framework, which represents a novel approach to machine learning. In this framework, LLMs are viewed as function approximators, where the text prompt serves as the parameter. This view draws a striking parallel to general-purpose computer systems, where performance is determined by the program—in this case, the textual prompt.
Advantages of VML
- Interpretability
A standout feature of the VML framework is its strong interpretability. By utilizing human-readable text prompts to represent functions, VML enables easy understanding and tracing of model behavior and potential failures. This transparency offers a significant improvement over traditional neural networks, which are often opaque in their decision-making. - Unified Representation
VML provides a unified representation for both data and model parameters using tokens. This contrasts with numerical machine learning, where data and model parameters are typically treated as separate entities. The token-based approach in VML simplifies the learning process and provides a more coherent framework for handling diverse machine learning tasks. - Flexibility and Effectiveness
The VML framework has demonstrated effectiveness across various machine learning tasks, including regression, classification, and medical image analysis.
Empirical Results: VML in Action
VML has shown promising results in several areas of machine learning:
- Regression Tasks
In linear regression, VML accurately learns the underlying function, showcasing its ability to approximate mathematical relationships. In more complex tasks like sinusoidal regression, VML outperforms traditional neural networks, especially in extrapolation tasks, when provided with the appropriate prior knowledge. - Classification Tasks
VML excels in both simple and non-linear classification tasks. For example, in the two-blob classification problem, it learns an efficient decision boundary quickly. In non-linear cases like the two-circle classification problem, VML incorporates prior knowledge effectively to generate accurate results. Its ability to explain its decision-making process in natural language enhances its interpretability and provides valuable insights into its learning progress. - Medical Image Classification
VML also demonstrates potential in medical applications, such as pneumonia detection from X-rays. The framework improves over training epochs and benefits from the integration of domain-specific prior knowledge. Its interpretable nature allows medical professionals to validate the models, making it especially useful in sensitive domains. - Comparison with Prompt Optimization Methods
Compared to prompt optimization methods, VML offers superior performance by capturing detailed, data-driven insights. While prompt optimization often produces general descriptions, VML captures nuanced patterns and instructions, enhancing its predictive capabilities.
Challenges and Limitations
Despite its promising results, the VML framework faces several challenges:
- Training Variance
VML experiences relatively high variance during training, primarily due to the stochastic nature of language model inference. This can result in inconsistent model performance. - Numerical Precision Issues
Even though the LLM understands symbolic expressions, numerical precision issues can still lead to inaccuracies in tasks that require high precision. - Scalability Constraints
LLMs are limited by their context window, which constrains scalability for larger tasks. As task complexity increases, the model’s ability to process data within the available context becomes limited.
Future Directions
The challenges faced by VML suggest opportunities for future improvements. Researchers can focus on minimizing training variance, addressing numerical precision issues, and tackling scalability limitations to further enhance VML’s performance. These developments will help solidify VML’s role as an interpretable and effective machine learning methodology.
Conclusion
The Verbal Machine Learning (VML) framework represents a significant step forward in machine learning, offering a fresh perspective on how LLMs can be used as function approximators. By leveraging natural language prompts as parameters, VML combines interpretability, flexibility, and the ability to integrate domain-specific knowledge. While challenges remain, VML’s effectiveness in tasks such as regression, classification, and medical image analysis positions it as a promising tool for future machine learning applications.



