

The development of the Listening-while-Speaking Language Model (LSLM) marks a significant advancement in human-computer interaction (HCI) by addressing the limitations of current speech-language models (SLMs) in real-time, uninterrupted dialogue. Traditional SLMs operate in turn-based systems, where listening and speaking occur in isolated phases, which can cause delays and fail to handle real-time interruptions effectively. This turn-based interaction model, while common, limits the natural flow of conversation and complicates use cases that require dynamic, fluid exchanges.
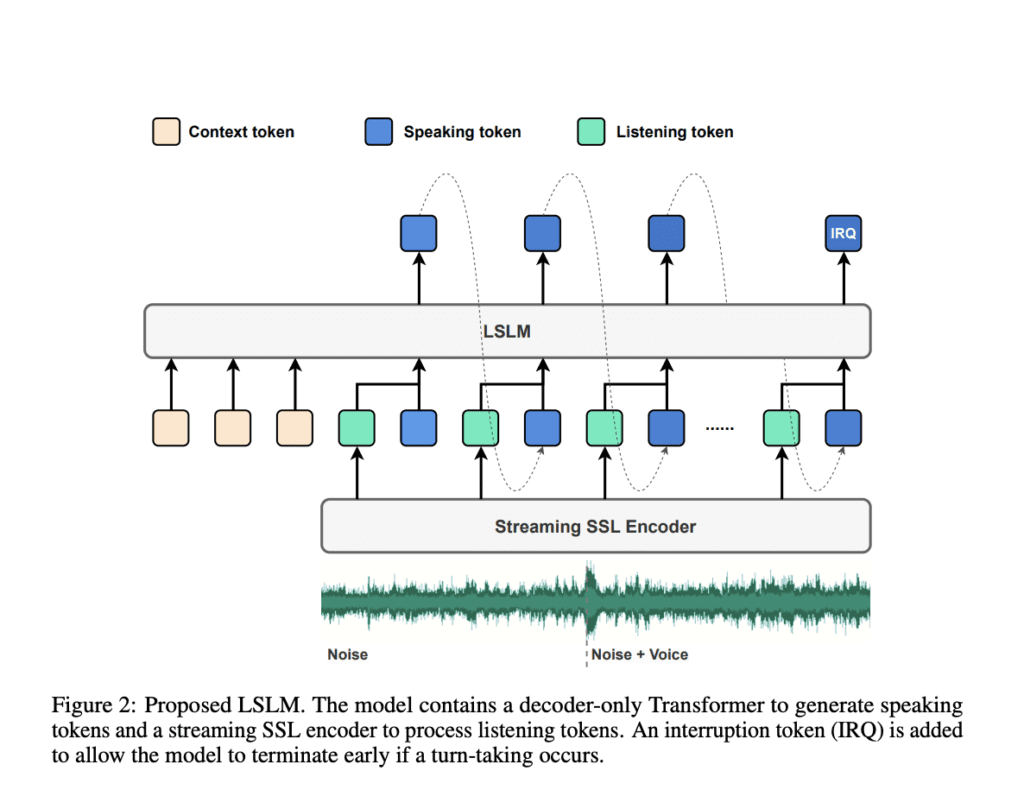
In contrast, the LSLM, developed by researchers from Shanghai Jiao Tong University and ByteDance, introduces an end-to-end solution for continuous, real-time interaction. By integrating both listening and speaking capabilities into a single system, the LSLM overcomes these limitations and enables seamless conversation. The system uses an autoregressive token-based Text-to-Speech (TTS) model for speaking, and a streaming self-supervised learning (SSL) encoder for processing incoming audio. The innovative aspect of LSLM is its dual-channel design, allowing the model to listen and speak simultaneously, improving the model’s responsiveness and the flow of conversation.
The fusion of the listening and speaking channels in LSLM is achieved through three approaches: early fusion, middle fusion, and late fusion. After experimentation, middle fusion emerged as the most effective strategy, as it merges the two channels at each Transformer block, ensuring the system can handle interruptions and maintain a coherent conversational flow. This method allows the model to dynamically adjust to new inputs, whether it is responding to voice commands or adapting to noise from multiple speakers.
Performance tests of the LSLM were conducted in two scenarios: a command-based full duplex model (FDM) and a voice-based FDM. In the command-based setting, the model’s ability to process instructions amidst background noise was evaluated, while in the voice-based setting, its sensitivity to interruptions from different speakers was tested. The results demonstrated that LSLM excels in noisy environments and can seamlessly adapt to interruptions, ensuring continuous, high-quality interaction.
Overall, the Listening-while-Speaking Language Model represents a significant step forward in conversational AI by overcoming the drawbacks of turn-based systems. Its design not only enables real-time, natural interaction but also improves the overall user experience by handling interruptions smoothly. This development is a key example of how integrating full duplex capabilities into SLMs can enhance their real-world applications, particularly in environments where dynamic, fluid conversation is critical. The LSLM sets a new benchmark for future advancements in speech-based human-computer interaction, bringing us closer to achieving more natural and efficient dialogue systems.



