

IncarnaMind is pioneering advancements in Artificial Intelligence by empowering users to interact with their personal documents, whether in PDF or TXT format. As AI-driven solutions grow in popularity, the demand for querying documents using natural language has surged. Yet, challenges such as accuracy and context management persist, even with powerful models like GPT. IncarnaMind addresses these challenges with a unique architecture designed to enhance user-document interaction.
Key Features of IncarnaMind
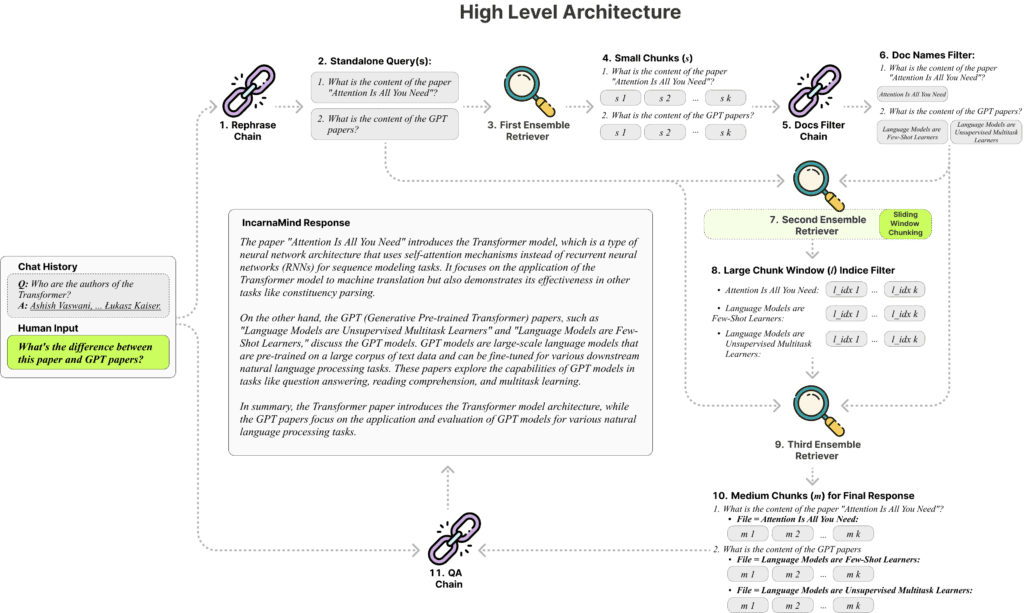
IncarnaMind’s system is powered by two core components: Sliding Window Chunking and an Ensemble Retriever. These innovations are essential for efficient and accurate information retrieval.
- Sliding Window Chunking
Unlike traditional Retrieval-Augmented Generation (RAG) methods that rely on fixed chunk sizes, IncarnaMind’s Sliding Window Chunking dynamically adjusts the size and position of the window. This adaptability allows the system to balance retrieving context-rich information and fine-grained details based on the complexity of the data and the user’s query. This makes IncarnaMind particularly effective at parsing and understanding intricate documents, ensuring precise information extraction. - Ensemble Retriever
This feature combines multiple retrieval methods to enhance query results. By sorting through coarse- and fine-grained data in the user’s source documents, the Ensemble Retriever strengthens the system’s responses, addressing the common issue of factual inaccuracies (or hallucinations) in language models. This multifaceted approach ensures that the presented information is both accurate and relevant.
Advantages Over Traditional Methods
IncarnaMind overcomes several limitations found in existing AI-driven document interaction tools:
- Adaptive Chunking for Varied Complexity
Conventional tools struggle with documents containing different levels of complexity due to their fixed chunk sizes. IncarnaMind’s adaptive chunking dynamically adjusts chunk sizes, improving data extraction accuracy by tailoring retrieval to the document’s content and context. - Balanced Retrieval
Many retrieval methods focus solely on precision or semantic understanding. IncarnaMind’s Ensemble Retriever balances both, delivering responses that are contextually appropriate and semantically rich. - Multi-Document Querying
Traditional solutions often fail to handle queries spanning multiple documents, limiting their utility in complex scenarios. IncarnaMind eliminates this hurdle by supporting multi-hop queries across multiple documents, enabling a more integrated and comprehensive understanding of the data.
Compatibility with Leading Language Models
IncarnaMind is designed to integrate seamlessly with a variety of leading large language models (LLMs), including the Llama2 series, Anthropic Claude, and OpenAI GPT. It is optimized for the Llama2-70b-chat model, which outperforms peers like GPT-4 and Claude 2.0 in reasoning and safety. However, this optimization comes with hardware requirements; the Llama2-70b-gguf quantized version demands over 35GB of GPU RAM. In such cases, the Together.ai API offers a practical alternative, supporting Llama2-70b-chat and other open-source models.
Conclusion
IncarnaMind represents a significant leap forward in how users interact with personal documents using AI. By addressing critical issues in document retrieval and offering robust compatibility with multiple LLMs, it is poised to become an indispensable tool for anyone seeking accurate and contextually aware document querying.



