

Large Language Models (LLMs) such as GPT-4, LLaMA, and Mistral are known for their powerful language understanding capabilities, primarily due to extensive training on vast datasets. However, their high resource demands make them less accessible for applications with limited computational resources. On the other hand, smaller models like MiniCPM, Phi, and Gemma offer greater scalability but often need targeted optimization to achieve comparable performance. This gap in efficiency and performance can be addressed by improving the models’ text embeddings—low-dimensional vector representations that capture the semantic meaning of text.
Researchers from Tsinghua University explored ways to enhance smaller language models by refining their text embeddings through contrastive fine-tuning. Their study focused on three smaller models—MiniCPM, Phi-2, and Gemma—and used the Natural Language Inference (NLI) dataset for fine-tuning. The results of their experiment demonstrated a significant improvement in text embedding quality across various benchmarks, with MiniCPM achieving a remarkable 56.33% performance gain.
The Role of Text Embeddings
Text embeddings are essential for natural language processing (NLP) tasks such as document classification, information retrieval, and similarity matching. Models like SBERT and Sentence T5 aim to provide versatile text encoding, while newer approaches like Contriever and E5 improve embeddings through multi-stage training strategies. Contrastive learning techniques, such as triplet loss and InfoNCE, focus on learning efficient representations by contrasting similar and dissimilar data points.
For smaller models like Phi, Gemma, and MiniCPM, the focus is on offering computationally efficient alternatives to larger models, without compromising on the quality of text embeddings. Super-tuning techniques like Adapter modules and LoRA (Low-Rank Adaptation) further allow task-specific fine-tuning of pre-trained models with reduced computational cost.
The Methodology: Contrastive Fine-Tuning and LoRA
The research targeted Semantic Textual Similarity (STS) tasks, aiming to enhance the performance of smaller models in generating contextually accurate text embeddings. By applying contrastive fine-tuning, the researchers trained the models to distinguish between similar and dissimilar text pairs, improving their ability to generate high-quality embeddings.
The methodology employed the InfoNCE objective, which uses in-batch and hard negatives to optimize the model’s ability to differentiate between related and unrelated text. To maintain computational efficiency, LoRA was used during fine-tuning. The NLI dataset, containing 275k samples, was processed for training and testing.
Evaluation and Results
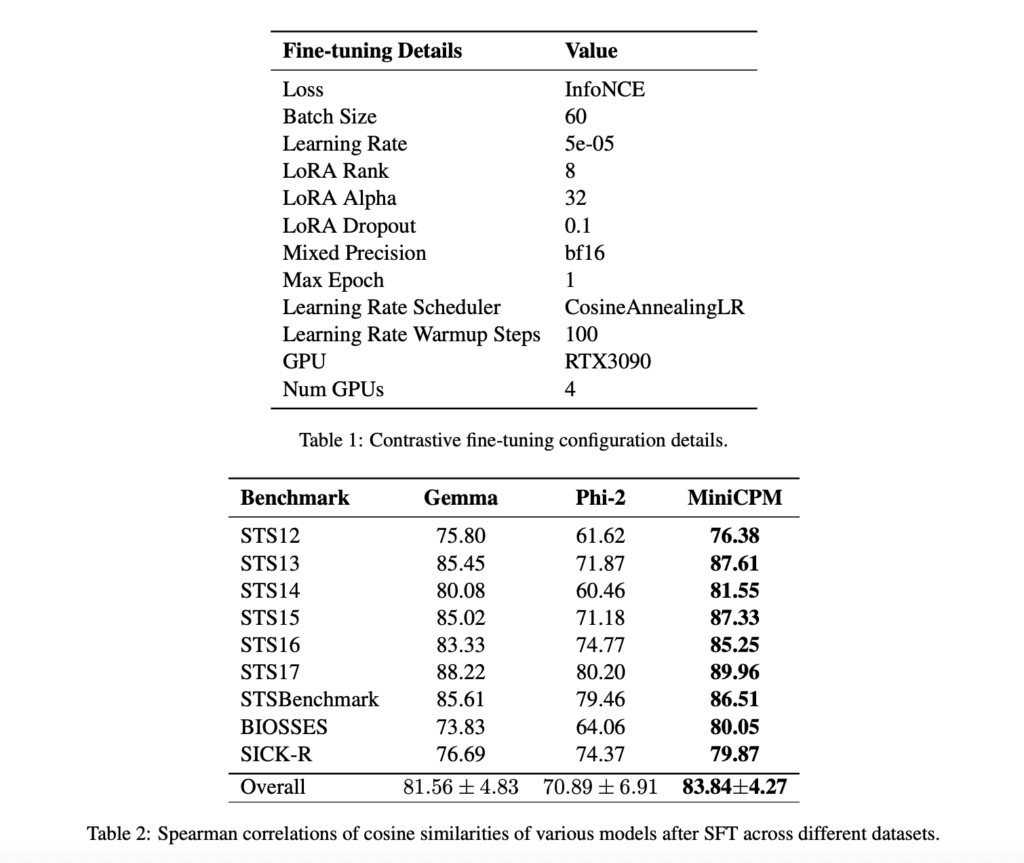
The researchers evaluated the performance of MiniCPM, Phi-2, and Gemma on 9 different STS benchmarks, including STS12-17, STSBenchmark, BIOSSES, and SICK-R. The evaluation involved measuring the similarity scores of sentence pairs using cosine similarity and Spearman correlation.
MiniCPM consistently outperformed the other models, achieving the highest Spearman correlation scores across all datasets. Fine-tuning with LoRA led to a 56-point improvement in MiniCPM’s performance. Ablation studies showed the importance of factors like learning rate, prompting, and the use of hard negative examples in improving model efficiency.
Conclusion
The study successfully demonstrated that contrastive fine-tuning on the NLI dataset could significantly improve the text embedding capabilities of smaller language models like MiniCPM. This process led to a 56.33% improvement in performance, allowing MiniCPM to surpass models like Phi-2 and Gemma across a variety of benchmarks. The fine-tuning approach, combined with the use of LoRA for computational efficiency, provides a scalable and resource-efficient alternative to larger models, making it suitable for applications with resource constraints.
This research not only addresses the underexplored area of optimizing smaller models but also contributes to making them more effective for real-world NLP tasks, offering a promising solution for resource-limited environments.



