

Pure Language Processing (NLP) has made significant strides in recent years, but one persistent challenge remains: hallucination, where models generate incorrect or nonsensical information. To address this issue, Retrieval-Augmented Generation (RAG) systems have been introduced, which incorporate external data retrieval to improve the accuracy of generated responses. Despite the progress, RAG systems still face challenges related to their reliability and effectiveness in providing accurate responses across various domains.
A major issue with current RAG evaluation methods is the focus on general knowledge, with insufficient emphasis on specialized fields such as finance, healthcare, and the legal sector. Evaluating the performance of RAG systems in these vertical domains is difficult due to the lack of high-quality, domain-specific datasets capable of testing the models’ ability to handle specialized knowledge. Traditional evaluation metrics used for NLP tasks, such as F1, BLEU, ROUGE-L, and EM for answer generation, and Hit Rate, MRR, and NDCG for retrieval evaluation, are limited in their ability to assess the generative performance of RAG models, particularly in vertical domains.
The Need for a Stronger Evaluation Framework
Existing evaluation metrics are increasingly being supplemented by newer approaches that leverage LLM-generated data to assess contextual relevance, faithfulness, and informativeness. However, these metrics lack the nuance needed to effectively evaluate the generative capabilities of RAG systems in specific domains. To address these shortcomings, a more robust framework for RAG evaluation is essential.
Researchers from Tsinghua University, Beijing Normal University, University of Chinese Academy of Sciences, and Northeastern University introduced the RAGEval framework to address these challenges. This framework is designed to automatically generate evaluation datasets tailored to specific domains, allowing for more accurate assessments of RAG model performance in these fields.
RAGEval Framework: A Comprehensive Approach
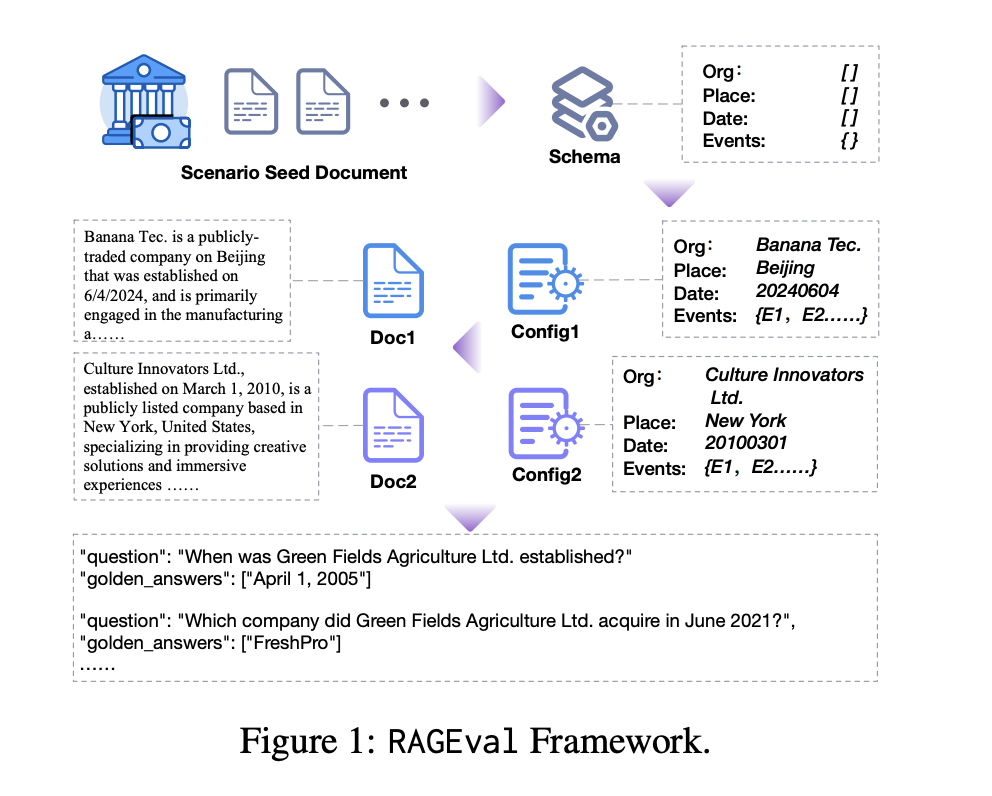
The RAGEval framework follows a systematic approach to improve the accuracy and reliability of RAG model evaluations. The process starts with summarizing a schema from seed documents, generating diverse documents, and creating question-answer pairs (QAPs) based on these configurations. These QAPs are then evaluated for completeness, hallucination, and irrelevance, ensuring that the evaluation process captures important aspects of factual accuracy.
The RAGEval pipeline follows a “schema-configuration-document-QAR-keypoint” flow, designed to ensure robustness and reliability. It generates a schema that encapsulates key domain-specific knowledge, from which configurations are created. These configurations help generate a variety of documents that are then used to produce question-answer pairs, which are ultimately evaluated for completeness and relevance.
A hybrid approach is employed to generate these configurations, combining rule-based methods for high accuracy and LLM-based techniques for generating more complex, varied content. Rule-based methods ensure consistency, especially for structured data, while LLMs generate diverse, contextually relevant content. This method ensures the produced documents are factually accurate and domain-specific.
Experimental Results and Validation
Experimental results showed that the RAGEval framework is highly effective at producing accurate, high-quality content across various domains. Human evaluation confirmed that the generated documents were clear, specific, and closely resembled real-world documents. Automated metrics aligned well with human judgment, validating their reliability in reflecting model performance.
In terms of performance, GPT-4o outperformed other models, achieving the highest Completeness scores—0.5187 for Chinese and 0.6845 for English. However, the gap with top-performing open-source models like Qwen1.5-14B-chat and Llama3-8B-Instruct was small. For instance, Qwen1.5-14B-chat scored 0.4926 in Chinese, while Llama3-8B-Instruct scored 0.6524 in English. These results suggest that open-source models, with further development, could significantly close the performance gap with proprietary models.
Conclusion
The RAGEval framework offers a comprehensive solution for evaluating RAG models, especially in specialized domains like finance, healthcare, and law. By focusing on domain-specific factual accuracy, it addresses the limitations of current benchmarks and enhances the reliability of RAG systems. Researchers and developers are encouraged to leverage frameworks like RAGEval to ensure their models meet the specific needs of their application domains, paving the way for future advancements in both proprietary and open-source RAG models.



