

IncarnaMind is main the best way in Synthetic Intelligence by enabling customers to have interaction with their private papers, whether or not they’re in PDF or TXT format. The need of having the ability to question paperwork in pure language has elevated with the introduction of AI-driven options. Nonetheless, issues nonetheless exist, particularly in relation to accuracy and context administration, even with robust fashions like GPT. Utilizing a singular structure supposed to enhance user-document interplay, IncarnaMind has tackled these issues.
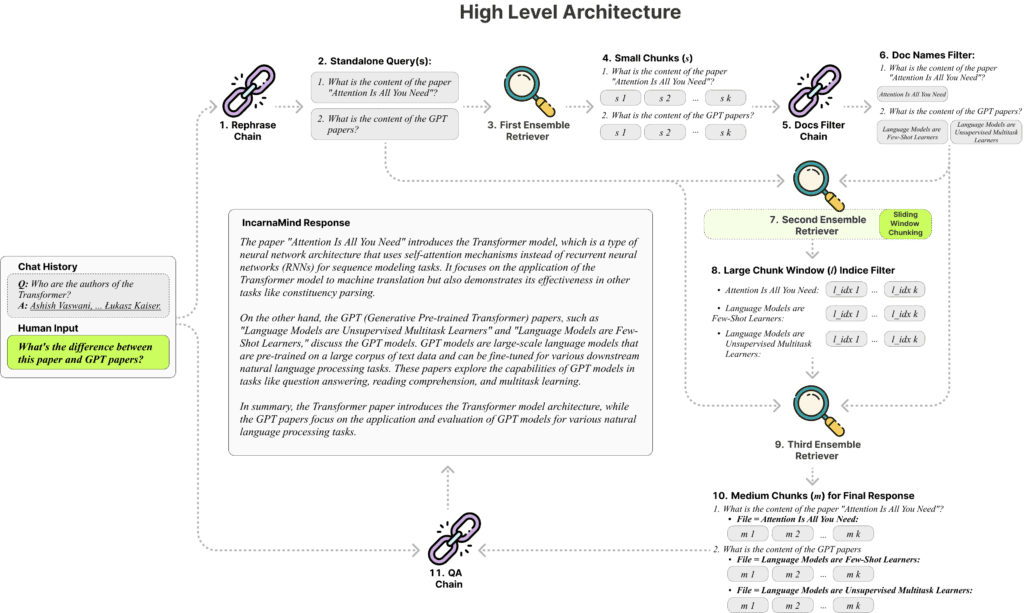
Sliding Window Chunking and an Ensemble Retriever mechanism are the 2 important elements of IncarnaMind, and they’re each important for efficient and environment friendly data retrieval from paperwork.
- Sliding Window Chunking: IncarnaMind’s Sliding Window Chunking dynamically modifies the window’s dimension and place in distinction to standard Retrieval-Augmented Technology (RAG) strategies, which depend upon fastened chunk sizes. Relying on the complexity of the info and the consumer’s question, this adaptive approach ensures that the system can steadiness between acquiring extra complete, contextually wealthy data and fine-grained particulars. This method makes the system way more able to parsing and comprehending complicated paperwork, which makes it an efficient instrument for retrieving detailed data.
- Ensemble Retriever: This method improves queries even additional by integrating a number of retrieval methods. The Ensemble Retriever enhances the LLM’s responses by enabling IncarnaMind to successfully type by means of each coarse- and fine-grained information within the consumer’s floor fact paperwork. By guaranteeing that the fabric introduced is correct and related, this multifaceted retrieval technique helps alleviate the prevalent concern of factual hallucinations continuously noticed in LLMs.
One in all its biggest benefits is that IncarnaMind can clear up a few of the enduring issues that different AI-driven doc interplay applied sciences nonetheless face. As a result of conventional instruments use a single chunk dimension for data retrieval, they continuously have hassle with totally different ranges of information complexity. That is addressed by IncarnaMind’s adaptive chunking approach, which permits for extra correct and pertinent information extraction by modifying chunk sizes primarily based on the content material and context of the doc.
Most retrieval strategies consider both exact information retrieval or semantic understanding. These two elements are balanced by IncarnaMind’s Ensemble Retriever, which ensures responses which might be each semantically wealthy and contextually acceptable. The shortcoming of many present options to question multiple doc without delay restricts their use in situations involving a number of paperwork. IncarnaMind removes this impediment by enabling multi-hop queries over a number of paperwork without delay, offering a extra thorough and built-in comprehension of the info.
IncarnaMind is made to be adaptable and work with many different LLMs, such because the Llama2 collection, Anthropic Claude, and OpenAI GPT. The Llama2-70b-chat mannequin, which has demonstrated the perfect efficiency by way of reasoning and security when in comparison with different fashions like GPT-4 and Claude 2.0, is the mannequin for which the instrument is particularly optimized. Nonetheless, some customers could discover this to be a disadvantage because the Llama2-70b-gguf quantized model requires greater than 35GB of GPU RAM to execute. The Collectively.ai API, which helps llama2-70b-chat and different open-source fashions, offers a workable substitute in these conditions.
In conclusion, with IncarnaMind, AI will considerably advance how customers work together with private papers. It’s well-positioned to emerge as a vital instrument for anybody requiring correct and contextually conscious doc querying, because it tackles vital points in doc retrieval and offers robust interoperability with a number of LLMs.



