

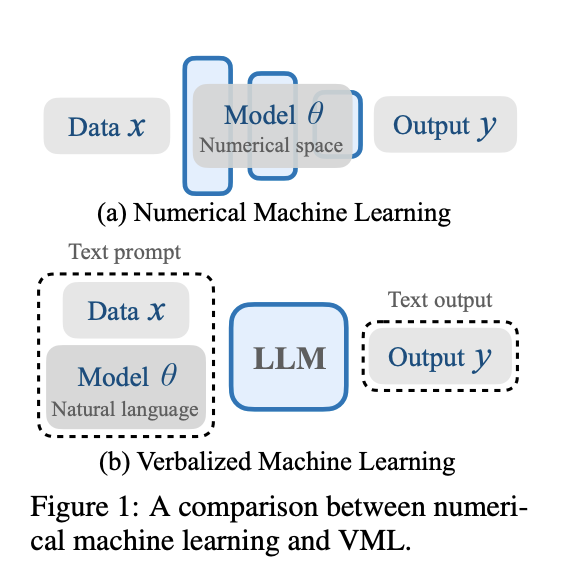
Large Language Fashions (LLMs) have revolutionized problem-solving in machine learning, shifting the paradigm from typical end-to-end teaching to utilizing pretrained fashions with rigorously crafted prompts. This transition presents an fascinating dichotomy in optimization approaches. Normal methods comprise teaching neural networks from scratch using gradient descent in a gentle numerical space. In distinction, the rising method focuses on optimizing enter prompts for LLMs in a discrete pure language space. This shift raises a compelling question: Can a pretrained LLM function as a system parameterized by its pure language speedy, analogous to how neural networks are parameterized by numerical weights? This new methodology challenges researchers to rethink the fundamental nature of model optimization and adaptation throughout the interval of large-scale language fashions.
Researchers have explored various functions of LLMs in planning, optimization, and multi-agent strategies. LLMs have been employed for planning embodied brokers’ actions and fixing optimization points by producing new choices based totally on earlier makes an try and their associated losses. Pure language has moreover been utilized to bolster learning in various contexts, corresponding to providing supervision for seen illustration learning and creating zero-shot classification requirements for pictures.
Instant engineering and optimization have emerged as important areas of analysis, with fairly a number of methods developed to harness the reasoning capabilities of LLMs. Automated speedy optimization methods have been proposed to chop again the handbook effort required in designing environment friendly prompts. Moreover, LLMs have confirmed promise in multi-agent strategies, the place they will assume completely totally different roles to collaborate on difficult duties.
Nonetheless, these present approaches normally consider explicit functions or optimization methods with out completely exploring the potential of LLMs as function approximators parameterized by pure language prompts. This limitation has left room for model new frameworks that will bridge the opening between typical machine learning paradigms and the distinctive capabilities of LLMs.
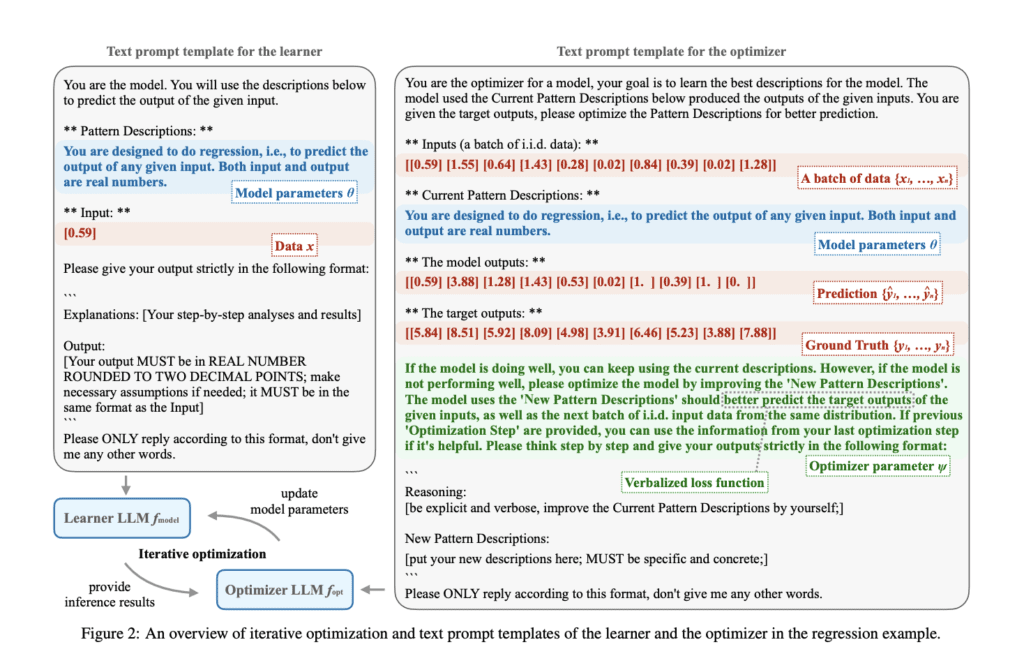
Researchers from the Max Planck Institute for Intelligent Packages, the Faculty of Tübingen, and the Faculty of Cambridge launched the Verbal Machine Finding out (VML) framework, a novel methodology to machine learning by viewing LLMs as function approximators parameterized by their textual content material prompts. This angle attracts an intriguing parallel between LLMs and general-purpose laptop techniques, the place the efficiency is printed by the working program or, on this case, the textual content material speedy. The VML framework affords an a variety of benefits over typical numerical machine learning approaches.
A key attribute of VML is its sturdy interpretability. By means of the usage of completely human-readable textual content material prompts to characterize capabilities, the framework permits for simple understanding and tracing of model habits and potential failures. This transparency is an enormous enchancment over the typically opaque nature of typical neural networks.
VML moreover presents a unified illustration for every data and model parameters in a token-based format. This contrasts with numerical machine learning, which normally treats data and model parameters as distinct entities. The unified methodology in VML in all probability simplifies the tutorial course of and provides a additional coherent framework for coping with various machine-learning duties.

The outcomes of the VML framework reveal its effectiveness all through various machine-learning duties, along with regression, classification, and movie analysis. Proper right here’s a summary of the essential factor findings:
VML reveals promising effectivity in every simple and complex duties. For linear regression, the framework exactly learns the underlying function, demonstrating its potential to approximate mathematical relationships. In further difficult eventualities like sinusoidal regression, VML outperforms typical neural networks, significantly in extrapolation duties, when equipped with acceptable prior knowledge.
In classification duties, VML shows adaptability and interpretability. For linearly separable data (two-blob classification), the framework shortly learns an environment friendly dedication boundary. In non-linear cases (two circles classification), VML effectively incorporates prior data to achieve right outcomes. The framework’s potential to elucidate its decision-making course of by pure language descriptions provides helpful insights into its learning improvement.
VML’s effectivity in medical image classification (pneumonia detection from X-rays) highlights its potential in real-world functions. The framework reveals enchancment over teaching epochs and benefits from the inclusion of domain-specific prior data. Notably, VML’s interpretable nature permits medical professionals to validate found fashions, an important attribute in delicate domains.
As compared with speedy optimization methods, VML demonstrates a superior potential to check detailed, data-driven insights. Whereas speedy optimization normally yields widespread descriptions, VML captures nuanced patterns and pointers from the data, enhancing its predictive capabilities.
Nonetheless, the outcomes moreover reveal some limitations. VML shows a relatively large variance in teaching, partly due to the stochastic nature of language model inference. Moreover, numerical precision factors in language fashions can lead to turning into errors, even when the underlying symbolic expressions are precisely understood.
No matter these challenges, the overall outcomes level out that VML is a promising methodology for performing machine learning duties, offering interpretability, flexibility, and the ability to incorporate space data efficiently.

This analysis introduces the VML framework, which demonstrates effectiveness in regression and classification duties and validates language fashions as function approximators. VML excels in linear and nonlinear regression, adapts to quite a few classification points, and divulges promise in medical image analysis. It outperforms typical speedy optimization in learning detailed insights. Nonetheless, limitations embody extreme teaching variance as a consequence of LLM stochasticity, numerical precision errors affecting turning into accuracy, and scalability constraints from LLM context window limitations. These challenges present options for future enhancements to bolster VML’s potential as an interpretable and extremely efficient machine-learning methodology.



