

Inside the realm of human-computer interaction (HCI), dialogue stands out as basically probably the most pure sort of communication. The looks of speech language fashions (SLMs) has significantly enhanced speech-based conversational AI, however these fashions keep constrained to turn-based interactions, limiting their applicability in real-time conditions. This gap in real-time interaction presents a significant drawback, considerably in situations requiring speedy ideas and dynamic conversational stream. The dearth to take care of interruptions and protect seamless interaction has spurred researchers to find full duplex modeling (FDM) in interactive speech language fashions (iSLM). Addressing this drawback, the evaluation introduces the Listening-while-Speaking Language Model (LSLM), an trendy design to permit real-time, uninterrupted interaction by integrating listening and speaking capabilities inside a single system.
Current methods in speech-language fashions typically include turn-based strategies, the place listening and speaking occur in isolated phases. These strategies normally make use of separate automated speech recognition (ASR) and text-to-speech (TTS) modules, leading to latency factors and an incapability to take care of real-time interruptions efficiently. Notable fashions like SpeechGPT and LauraGPT have superior conversational AI. However, they proceed to be restricted to these turn-based paradigms, unable to supply the fluid interaction required for additional pure human-computer dialogue.
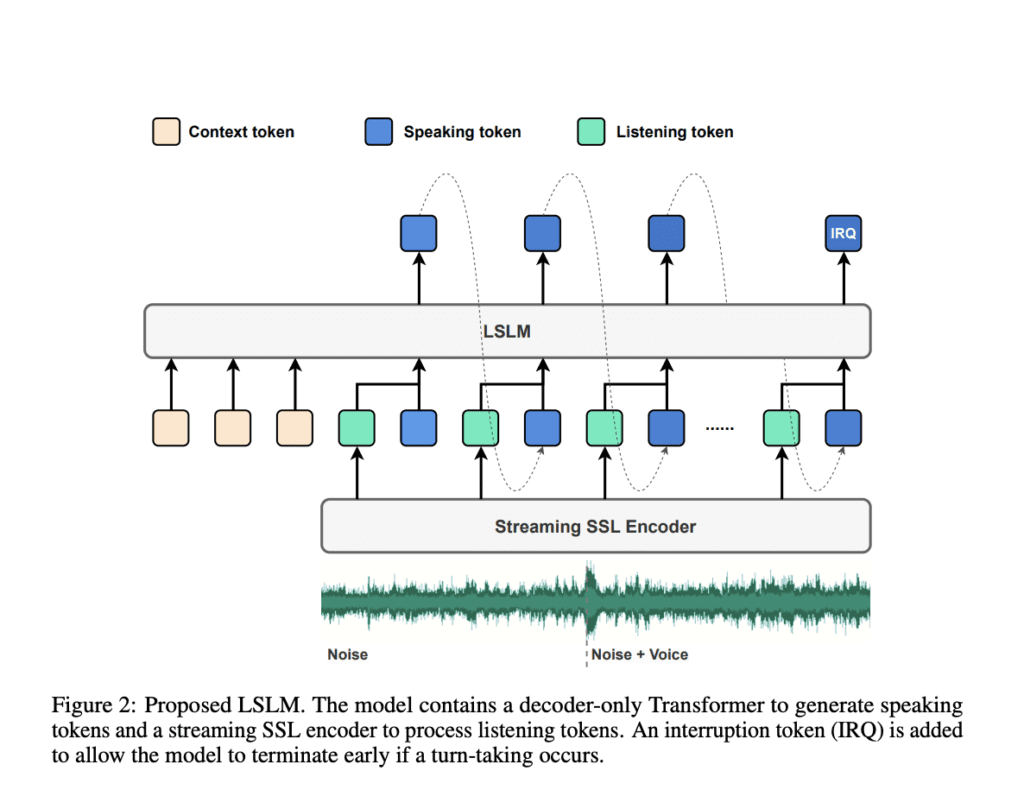
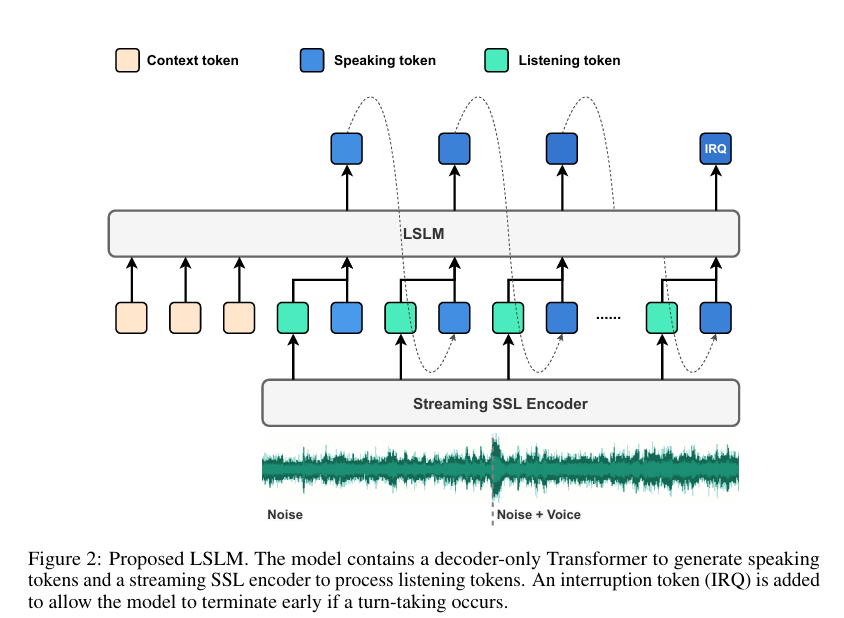
To beat these limitations, a workers of researchers from Shanghai Jiao Tong School and ByeDance counsel the LSLM, an end-to-end system designed to concurrently perform every listening and speaking. This model employs a token-based decoder-only TTS for speech period and a streaming self-supervised learning (SSL) encoder for real-time audio enter. The LSLM’s distinctive technique lies in its talent to fuse these channels, enabling it to detect real-time turn-taking and reply dynamically. By exploring three fusion strategies—early fusion, middle fusion, and late fusion—the researchers acknowledged middle fusion as a result of the optimum stability between speech period and real-time interaction capabilities.
The LSLM’s construction revolves spherical its dual-channel design. For speaking the model makes use of an autoregressive token-based TTS system. In distinction to earlier fashions that rely upon autoregressive and non-autoregressive approaches, the LSLM simplifies this by using discrete audio tokens, enhancing real-time interaction, and eliminating the need for in depth processing sooner than speech synthesis. The speaking channel generates speech tokens based totally on the given context with a vocoder, which converts these tokens into audible speech. This setup permits the model to focus additional on semantic information, bettering the readability and relevance of its responses.
On the listening side, the model employs a streaming SSL encoder to course of incoming audio alerts continuously. This encoder converts audio enter into regular embeddings after which initiatives it into an space that could be processed alongside the speaking tokens. These channels are built-in by the use of one among three fusion methods, with middle fusion rising as the perfect. On this technique, the listening and speaking channels are merged at each Transformer block, allowing the model to leverage every channels’ information all via the speech period course of. This fusion method ensures the LSLM can take care of interruptions simply and protect a coherent and responsive dialogue stream.
Effectivity evaluation of the LSLM was carried out beneath two experimental settings: command-based FDM and voice-based FDM. Inside the command-based state of affairs, the model was examined on its talent to answer to specific directions amidst background noise. In distinction, the voice-based state of affairs evaluated its sensitivity to interruptions from diverse audio system. The outcomes demonstrated the LSLM’s robustness to noisy environments and expertise to acknowledge and adapt to new voices and instructions. The middle fusion method, significantly, balanced the requires of real-time interaction and speech period, providing a seamless shopper experience.
The Listening-while-Speaking Language Model (LSLM) represents a significant leap forward in interactive speech-language fashions. By addressing the restrictions of turn-based strategies and introducing a sturdy, real-time interaction performance, the LSLM paves one of the best ways for additional pure and fluid human-computer dialogues. The evaluation highlights the importance of integrating full duplex capabilities into SLMs, showcasing how such developments can enhance the applicability of conversational AI in real-world conditions. Via its trendy design and spectacular effectivity, the LSLM models a model new regular for future developments in speech-based HCI.



